Abstract
In this work, we focus on improving the captions generated by image-caption generation systems.
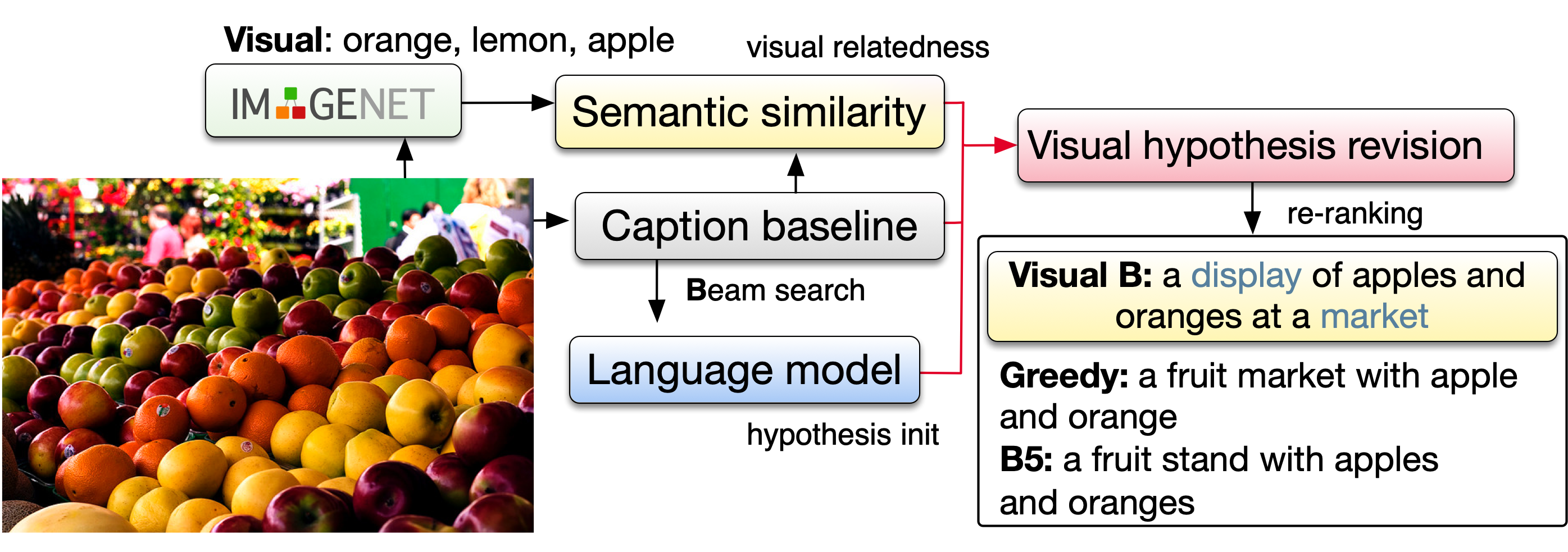
We propose a novel re-ranking approach that
leverages visual-semantic measures to identify the ideal caption that maximally captures the visual information in the image.
Our re-ranker utilizes the Belief Revision framework (Blok et. al. 2003) to calibrate the original likelihood of the top-n
captions by explicitly exploiting the semantic relatedness between the depicted caption and the visual context.
Our experiments demonstrate the utility of our approach, where we observe that our re-ranker can enhance the performance
of a typical image-captioning system without the necessity of any additional training or fine-tuning.
Citation
@article{sabir2022belief,
title={Belief Revision based Caption Re-ranker with Visual Semantic Information},
author={Sabir, Ahmed and Moreno-Noguer, Francesc and Madhyastha, Pranava and Padr{\'o}, Llu{\'\i}s},
journal={arXiv preprint arXiv:2209.08163},
year={2022}
}