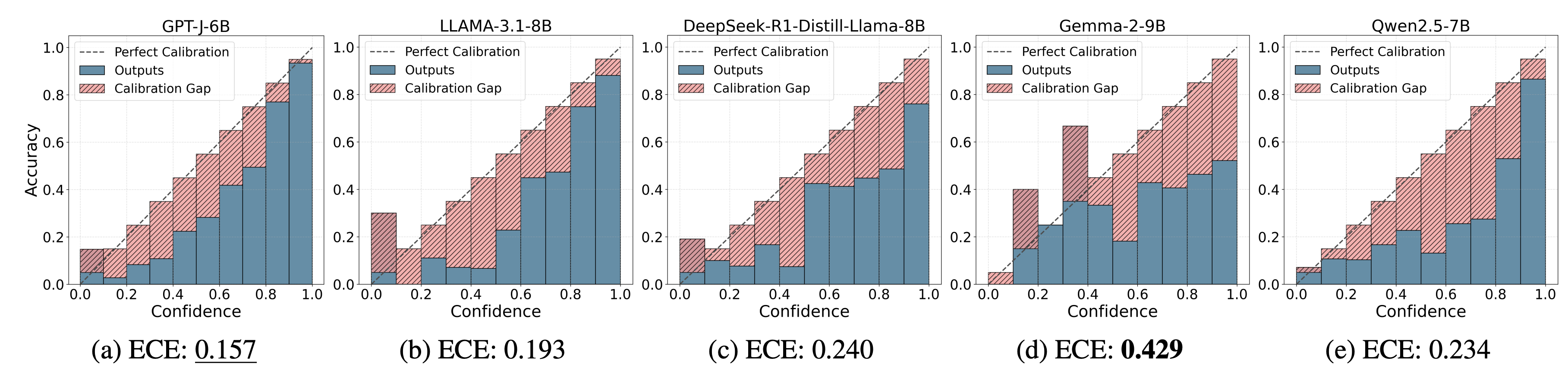
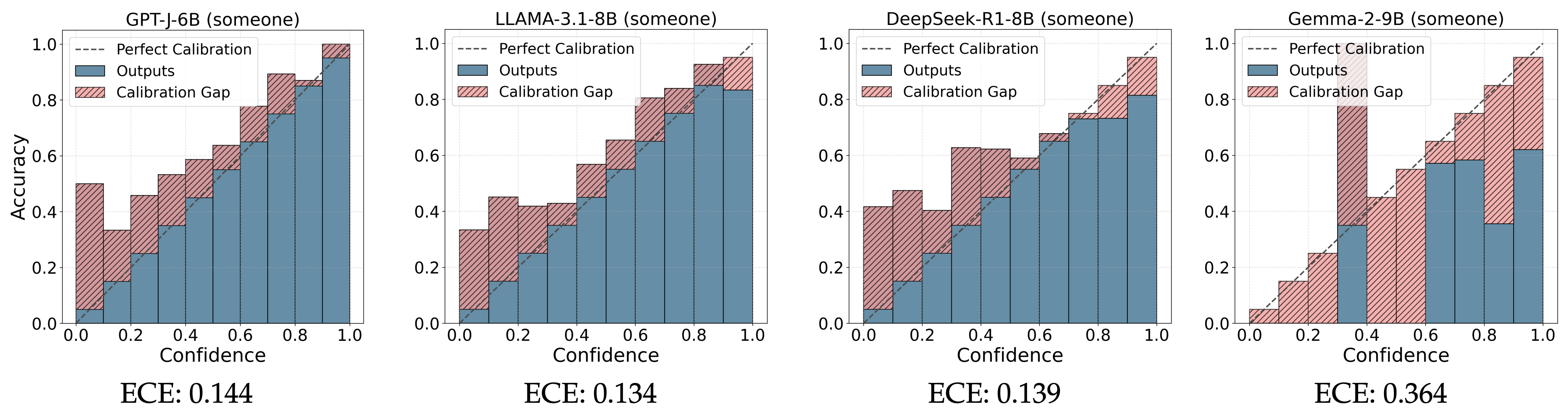
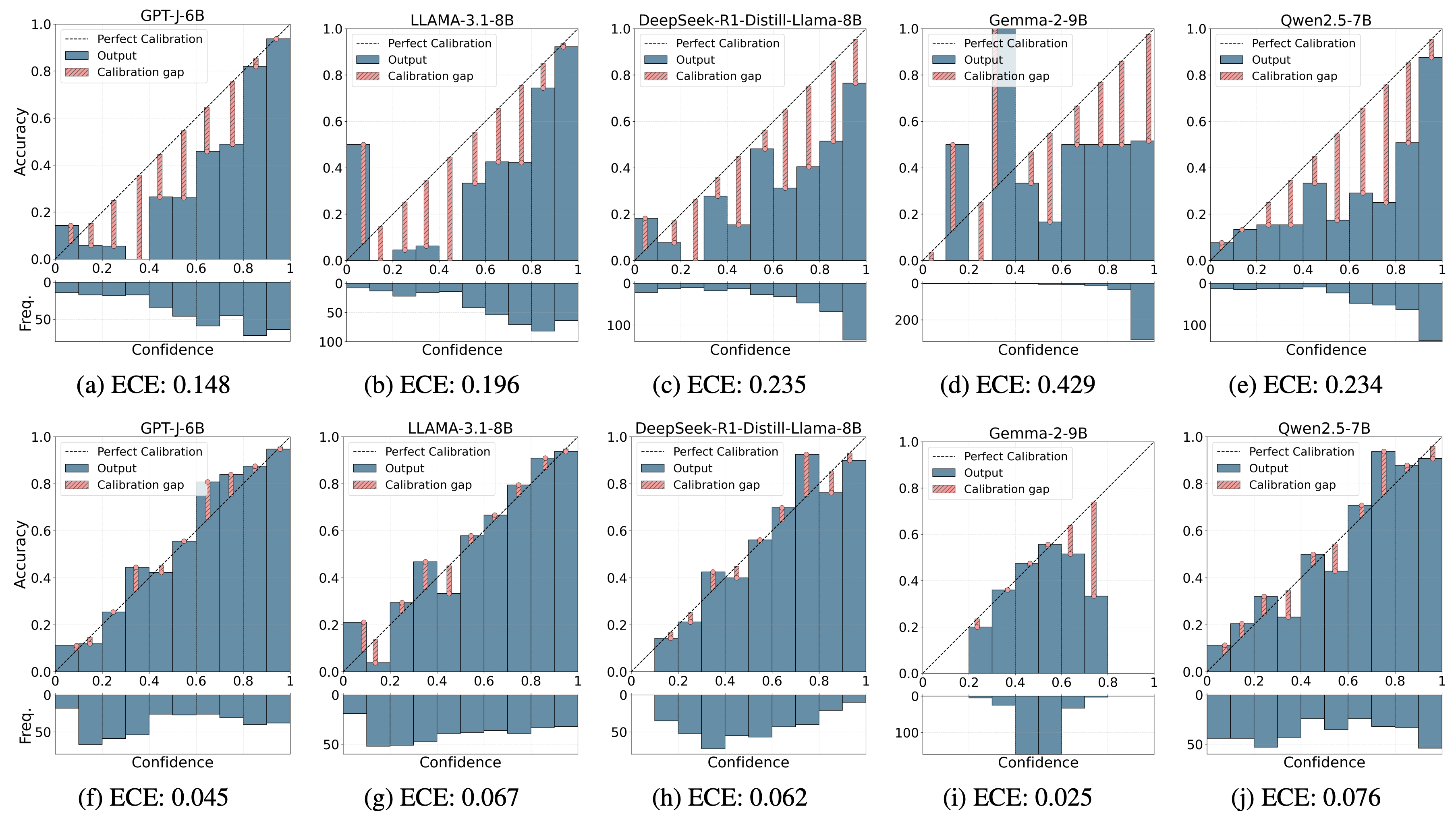
Experiment: Last Cloze Task
The primary focus of the analysis is to assess the models’ bias and confidence in predicting pronouns at the end of sentences, GenderLex dataset (last cloze), meaning that the model has access to the full context of the sentence before scoring a biased pronoun.
| Model | Standard Calibration Metrics | Gender-ECE | Human | |||||
|---|---|---|---|---|---|---|---|---|
| ECE | MacroCE | ICE | Brier Score | Group | M | F | ||
| GPT-J-6B | 0.076 | 0.453 | 0.374 | 0.432 | 0.076 | 0.085 | 0.066 | 0.715 |
| LLAMA-3.1-8B | 0.111 | 0.466 | 0.371 | 0.446 | 0.111 | 0.112 | 0.109 | 0.727 |
| Gemma-2-9B | 0.327 | 0.493 | 0.390 | 0.559 | 0.267 | 0.330 | 0.204 | 0.617 |
| Qwen2.5-7B | 0.106 | 0.476 | 0.422 | 0.385 | 0.107 | 0.052 | 0.162 | 0.637 |
| Falcon-3-7B | 0.161 | 0.491 | 0.449 | 0.356 | 0.149 | 0.081 | 0.217 | 0.605 |
| DeepSeek-8B | 0.085 | 0.461 | 0.369 | 0.470 | 0.090 | 0.074 | 0.106 | 0.686 |
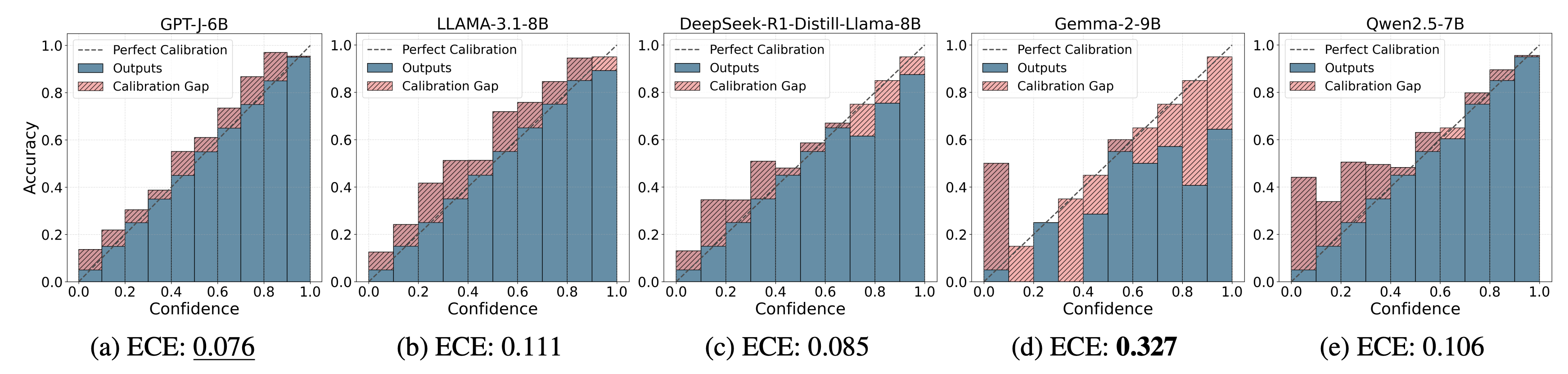
Finding: GPT-J-6B exhibits the best calibration (lowest ECE), while Gemma-2-9B performs the worst overall, consistently producing incorrect outcomes with a high disparity toward the female group.