Word to Sentence Visual Semantic Similarity for Caption Generation: Lessons learned
In this blog post, I will share with you some insight and lessons learned from our recent work
Introduction#
Image Captioning System. Automatic image captioning is a fundamental task that incorporates vision and language. The task can be tackled in two stages: first, image-visual information extraction and then linguistic description generation.
Most models couple the relations between visual and linguistic information via a Convolutional Neural Network (CNN) to encode the input image and Long Short Term Memory for language generation
Visual Context Image Captioning System. Modern sophisticated image captioning systems focus heavily on visual grounding to capture real-world scenarios. Early works
Inspired by these works,
Beam Search Caption Extraction. We employ the three most common architectures for caption generation to extract the top beam search. The first baseline is based
on the standard shallow CNN-LSTM model
Learning Word to Sentence Visual Semantic
Problem Formulation. Beam search is the dominant method for approximate decoding in structured prediction tasks such as machine translation, speech recognition, and image captioning. The larger beam size allows the model to perform a better exploration of the search space compared to greedy decoding. Our goal is to leverage the visual context information of the image to re-rank the candidate sequences obtained through the beam search, thereby moving the most visually relevant candidate up in the list, as well as moving incorrect candidates down.
Word level similarity. To learn the semantic relation between a caption and its visual context in a word-level manner: first, we employ a bidirectional
LSTM based CopyRNN keyphrase extractor
Sentence level similarity. We fine-tune the BERT base model to learn the visual context information. The model learns a dictionary-like relation word-to-sentence paradigm. We use the visual data as context for the sentence via cosine distance.
BERT
Sentence RoBERTa
Fusion Similarity Expert. Product of experts (PoE)
\[ P\left(\mathbf{w} | \theta_{1} .. \theta_{n}\right)=\arg \max _{\mathbf{w}} \frac{\Pi_{m} p_{m}\left(\mathbf{w} | \theta_{m}\right)} {\sum_{\mathbf{c}} \Pi_{m} p_{m}\left(\mathbf{c} | \theta_{m}\right)} \]
where \(θm\) are the parameters of each model \(m\), \(pm(\mathbf{w}|θm)\) is the probability of \(\mathbf{w}\) under the model \(m\) and \(c\) are the indexes of all possible vector in the data space. Since we are just interested in retrieving the candidate caption with higher probability after re-ranking, we do not need to normalize. Therefore, we compute:
\[\arg \max _{\mathbf{w}} {\Pi_{m} p_{m}\left(\mathbf{w} | \theta_{m}\right)}\]
where, \(p_{m}\left(\mathbf{w} | \theta_{m}\right)\) are the probabilities (i.e. semantic relatedness score) assigned by each expert to the candidate caption \(\mathbf{w}\) with the semantic relation with the visual context of the image.
Dataset#
We evaluate the proposed approach on two different sized datasets. The idea is to evaluate our method on the most common caption dataset in two scenarios: (1) a shallow model CNN-LSTM (i.e. less data), as well as a system that is trained on a huge amount of data (e.g. Transformer).
♠ Flickr8k
♣ COCO
Visual Context Dataset. Since there are many public datasets for image captioning, they contain no textual visual information such as objects in the image. We enrich the two datasets, mentioned above, with textual visual context information.
In particular, to automate visual context generation and without the need for human labeling, we use ResNet-152
Evaluation Metric. We use the official COCO offline evaluation suite, producing several widely used caption quality
metrics: BLEU
Results and Analysis#
We use visual semantic information to re-rank candidate captions produced by out-of-the-box state-of-the-art caption generators. We extract top-20 beam search candidate captions from three different architectures
(1) standard CNN+LSTM model
| Model | B-4 | M | R | C | B-S | |||
| ♠ Show and Tell-BeamS |
0.035 | 0.093 | 0.270 | 0.035 | 0.8871 | |||
| Tell+VR_V1-BERT-Glove | 0.035 | 0.095 | 0.273 | 0.036 | 0.8855 | |||
| Tell+VR_V2-BERT-Glove | 0.037 | 0.099 | 0.277 | 0.041 | 0.8850 | |||
| Tell+VR_V1-RoBERTa-Glove (sts) | 0.037 | 0.101 | 0.273 | 0.036 | 0.8839 | |||
| Tell+VR_V2-RoBERTa-Glove (sts) | 0.035 | 0.095 | 0.273 | 0.036 | 0.8869 | |||
| ♣ VilBERT-BeamS |
0.336 | 0.271 | 0.543 | 1.027 | 0.9363 | |||
| Vil+VR_V1-BERT-Glove | 0.334 | 0.273 | 0.544 | 1.034 | 0.9365 | |||
| Vil+VR_V2-BERT-Glove | 0.334 | 0.273 | 0.545 | 1.034 | 0.9365 | |||
| Vil+VR_V1-RoBERTa-Glove (sts) | 0.335 | 0.273 | 0.544 | 1.036 | 0.9365 | |||
| Vil+VR_V2-RoBERTa-Glove (sts) | 0.338 | 0.272 | 0.545 | 1.040 | 0.9366 | |||
| ♣ Transformer-BeamS |
0.374 | 0.278 | 0.569 | 1.153 | 0.9399 | |||
| Trans+VR_V1-BERT-Glove | 0.371 | 0.278 | 0.567 | 1.149 | 0.9398 | |||
| Trans+VR_V2-BERT-Glove | 0.371 | 0.278 | 0.568 | 1.150 | 0.9399 | |||
| Trans+VR_V1-RoBERTa-Glove (sts) | 0.370 | 0.277 | 0.567 | 1.145 | 0.9395 | |||
| Trans+VR_V2-RoBERTa-Glove(sts) | 0.370 | 0.277 | 0.567 | 1.145 | 0.9395 | |||
| The ♠ refers to the Flikr 1730 test set from the Flikr8k dataset, and the ♣ refers to the COCO Caption Karpathy 5k test set. | ||||||||
Experiments applying different re-rankers to each base system are shown in Table 1 (above). The tested re-rankers are: (1) VR_BERT+GloVe, which uses BERT and GloVe similarity between the candidate caption and the visual context (top-k visual 1 (V_1) and visual 2 (V_2) during the inference once at a time) to obtain the re-ranked score. (2) VR_RoBERTa+GloVe, which carries out the same procedure using similarity produced by Sentence RoBERTa.
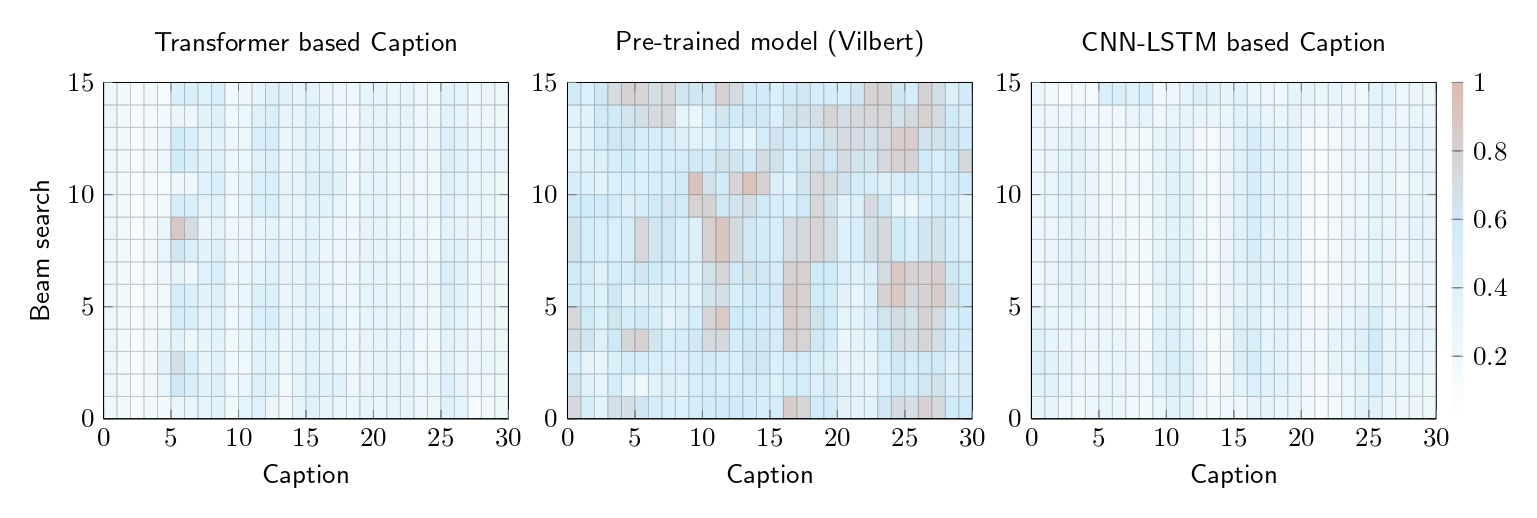
Our re-ranker produced mixed results as the model struggles when the beam search is less diverse. The model is therefore not able to select the most closely related caption to its environmental context as shown in Figure 2, which is a visualization of the final visual beam re-ranking.
Evaluation of Lexical Diversity. As shown in Table 2 (below), we evaluate the model from a lexical diversity perspective. We can conclude that we have (1) more vocabulary, and (2) the Unique
word per caption is also improved, even with a lower Type-Token Ratio TTR
Although this approach re-ranks higher diversity caption, the improvement is not strong enough to impact the benchmark result positively as shown in Table 1.
| Model | Voc | TTR | Uniq | WPC |
| ♠ Show and Tell-BeamS |
304 | 0.79 | 10.4 | 12.7 |
| Tell+VR-RoBERTa | 310 | 0.82 | 9.42 | 13.5 |
| ♣ VilBERT-BeamS |
894 | 0.87 | 8.05 | 10.5 |
| Vil+VR-RoBERTa | 953 | 0.85 | 8.86 | 10.8 |
| ♣ Transformer-BeamS |
935 | 0.86 | 7.44 | 9.62 |
| Trans+VR-BERT | 936 | 0.86 | 7.48 | 8.68 |
| Uniq and WPC columns indicate the average of unique/total words per caption, respectively. | ||||
| The ♠ refers to the Fliker 1730 test set, ♣ refers to the COCO Karpathy 5k test set. | ||||
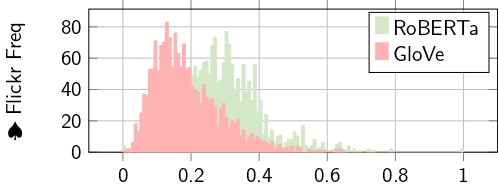
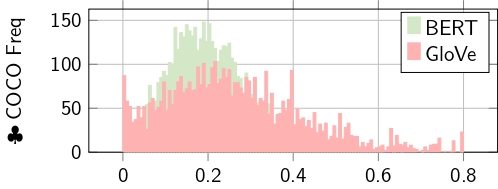
Ablation Study. We performed an ablation study to investigate the effectiveness of each model. As to the proposed architecture, each expert tried to learn different representations in a word and sentence manner. In this experiment, we trained each model separately, as shown in Table 3 (Bottom ♣). The GloVe as a stand-alone performed better than the combined model (and thus, the combined model breaks the accuracy). To investigate this even further we visualized each expert before the fusion layers as shown in Figure 3.
| Model | B-4 | M | R | C | B-S |
| Transformer-BeamS | 0.374 | 0.278 | 0.569 | 1.153 | 0.9399 |
| +VR-RoBERT-GloVe | 0.370 | 0.277 | 0.567 | 1.145 | 0.9395 |
| +VR-BERT-GloVe | 0.370 | 0.371 | 0.278 | 1.149 | 0.9398 |
| +VR-RoBERT-BERT | 0.369 | 0.278 | 0.567 | 1.144 | 0.9395 |
| +VR_V1-GloVe | 0.371 | 0.278 | 0.568 | 1.148 | 0.9398 |
| +VR_V2-GloVe | 0.371 | 0.371 | 0.278 | 1.149 | 0.9398 |
| The color represents Figure 3. ♣ Bottom Figure 3 shows that BERT is not contributing, as GloVe, to the final score. | |||||
Limitation. In contrast to CNN-LSTM (♠ top Figure 3), where each expert is contributing to the final decisions, we observed that having a shorter caption (with less context) can influence the BERT similarity score negatively. Therefore, the GloVe dominates as the main expert as shown in Figure 3 (♣ Bottom). Another limitation is the fluctuating of independent stand-alone word similarity score i.e. keyphrases from the caption and the visual sim(keyphrase, visual). Also, the visual classifier struggles with complex backgrounds (i.e. misclassified and hallucinated objects), which results in an inaccurate semantic score.
Conclusion#
In this work, we introduce an approach that overcomes the limitation of beam search and avoids re-training for better accuracy. We proposed a combined word and sentence visual beam search re-ranker. However, we discover that word and sentence similarity disagree with each other when the beam search is less diverse. Our experiments also highlight the usefulness of the model by showing successful cases.
We can also cite external publications.